This article is more than 1 year old
Walk with me... through a billion files. Slow down – admire the subset
Qumulo and the tree-walking problem
Analysis If you ask your notebook's filesystem how many MP3 files it is storing that haven’t been opened in 30 days, you can find the answer reasonably quickly. But ask an enterprise’s file system when it holds a million files and you have a big problem.
Ask this question of a file system that holds a billion files and your day just got a whole lot worse.
Here's a filesystem 101 to say why this happens.
A file system is like an upside-down tree structure of files in folders, with the folders forming a directory tree descending from a single root. Each node in this structure lists the files it contains, plus data about the files, and the sub-folders in contains. There is no central directory in one place listing all this stuff for the entire filesystem.
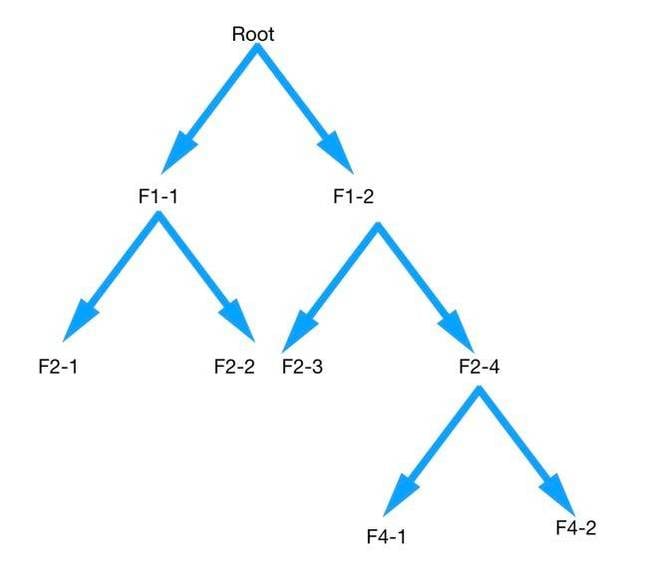
Upside-down file system tree structure
So, to answer the initial question: the system has to traverse or walk the file system tree and at each node (F1-1, F1-2) look for files with the .MP3 extension and their last opened date, adding them to a list if they match the filter criteria. If there is a nested sub-folder or sub-folders (F2-1, F2-2) it has to walk the tree down to the first one ( F2-1) node and repeat the process, and then repeat again for any sub-folder, until it gets to the bottom of that series of nodes, then walk back up until it gets to a node where there is another sub-folder (F2-2) listed and go to that, and so on ad infinitum, meaning the end of the file system.
Assume each node access requires a disk access and this takes 10 milliseconds; then a 10-node file system would take 100ms roughly plus the access needed to walk back up the tree; say 150ms being simplistic.
So, again, a 100-node file system would take 1,500ms, a thousand node one 15,000ms, a million node one 15,000,000ms and a billion node one 15,000,000,000ms - like we said, your day just got a whole lot worse because the tree walk is going to take days, 173.6 if our often suspect math is correct.
Qumulo CTO and co-founder Peter Godman, presenting to a press briefing, says these kind of numbers aren’t imaginary. A major DreamWorks picture needs 500 million files and legacy kit – meaning pre-2010 – can’t cope with this kind of filesystem request, going into a kind of tree-walk paralysis, which makes them hard to manage and optimise.
Qumulo says tree walks make data management tasks days to weeks long, leading to data blindness.

Qumulo co-founder and CEO Peter Godman
Seemingly simple requests – such as how many MP3 files there are that haven’t been opened in 30 days – are practically impossible to accomplish, let alone telling the filesystem to move them off to cheap back-end cloud storage.
Qumulo’s marketing VP, Jay Wampold, says: “When you have a billion anything, humans can’t manage it.”
As Godman says, the metadata processing involved becomes a problem in its own right: ”The metadata itself is a big data problem at scale” and with QF2 (Qumulo File Fabric) we have real-time control of files at scale.
You can’t retrofit the necessary metadata generation, storage and access to an existing file system. It has to be designed in, which it has been when it comes to Qumulo’s scale-out filesystem (QFS, with its underlying scalable block store (SBS).
There is a Qumulo database component, an extension of traditional file system metadata, which puts virtual fields in file metadata, and has an analytics capability.
Qumulo invented it and built it and it is distributed across nodes. It is the firm's own metadata database, and a property of its file system tree, not a separate "box" containing metadata.
A Qumulo QF2 technical overview (PDF) declares:
When you have a large numbers of files, the directory structure and file attributes themselves become big data. As a result, sequential processes such as tree walks, which are fundamental to legacy storage, are no longer computationally feasible. Instead, querying a large file system and managing it requires a new approach that uses parallel and distributed algorithms.
The technical paper says: “There is an inode B-tree, which acts as an index of all the files. The inode list is a standard file-system implementation technique that makes checking the consistency of the file system independent of the directory hierarchy. Inodes also help to make update operations such as directory moves efficient.
Files and directories are represented as B-trees with their own key/value pairs, such as the file name, its size and its access control list (ACL) or POSIX permissions.
This reliance on B-trees that point to virtualized protected block storage in SBS is one of the reasons that in QF2, a file system with a trillion files is feasible.
QumuloDB analytics are built in and integrated with the file system itself. Because the QF2 file system relies on B-trees, the analytics can use a system of real-time aggregates and information is available for timely processing without costly file system tree walks.
Read the technical overview to find out more. ®
