This article is more than 1 year old
What if I told you that flash drives could do their own processing?
ScaleFlux and NGD aim to wrangle data at drive-level
Part 2 Bringing compute to data aims to knock stored data access latency on its head by not moving masses of data across networks to host servers. Bringing compute to disk drives is facing an uphill struggle, but flash drives, with their much faster access, might have an easier time of it.
An opposing approach – bringing data to compute faster via NVMe over Fabrics – could roadblock flash drives with onboard compute. We'll look at that in a minute or two.
Two startups are involved in putting compute on flash drives – ScaleFlux and NGD Systems.
ScaleFlux
This company installs a Xilinx FPGA on its CSS 1000 flash drive board, calling it Computational Storage, and has the host server look after Flash Translation Layer (FTL) responsibilities.
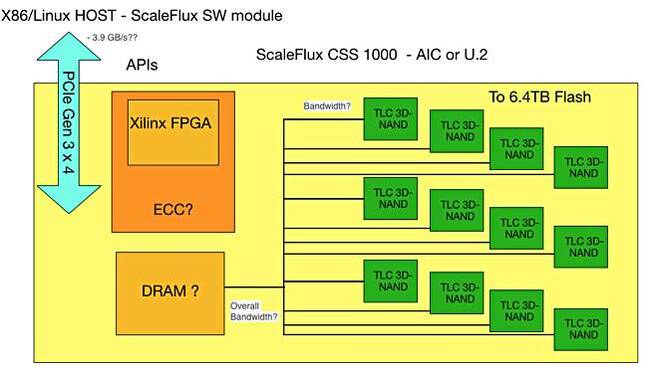
Our understanding of ScaleFlux compute + flash drive.
The CSS 1000 drive comes in a HHHL AIC format or U.2 2.5-inch format, and offers capacities up to 6.4TB using TLC (3bits/cell) 3D NAND. It says there can be up to eight CSS 1000 drives per server for a maximum of 51TB of capacity.

The x86 host server runs a ScaleFlux software module, which provides API access to the drive. The company says that, through a turnkey, easy-to-install software package, both low-latency storage IO and compute hardware acceleration are easily enabled without development effort or application recompilation.
ScaleFlux has offices in San Jose, Beijing and Yokohame City, Japan.
Chinese public cloud provider UCloud is a customer and ScaleFlux is partnered with server manufacturer Inspur to integrate its drives with Inspur servers. ScaleFlux has tested the effect of using its card to accelerate software such as Aerospike, PostgrSQL, and MySQL:
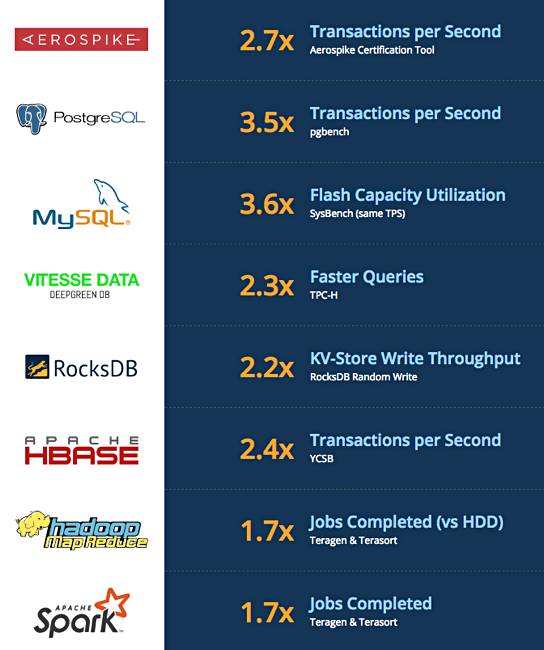
Its website has individually charted details and information about such product acceleration. For example, this is what it says about its performance with the NoSQL database Aerospike:
ScaleFlux CSS 1000 series demonstrates significantly more transactions per second compared to NVMe SSDs. This test was done with a 67 per cent read/33 per cent write ratio of 1.5 KB objects over 24 hours.
What this means is that code has already been written to run on the card's FPGA for these applications. ScaleFlux says it has started selling its CSS 10000 drives for revenue, shipping drives into multiple enterprise end-user production environments.
Co-founder and CEO Hao Zhong said: "From high transaction throughput and e-commerce payment environments to travel sites that demand real-time response to queries, our customers are getting more useful work from their volume flash storage deployments with CSS."
The company is expanding drive use into content delivery, search, HPC, AI and machine learning environments.
The next supplier has a different approach, with much higher capacity cards and an Arm processor, making it more easily programmable.
NGD Systems
Next Generation Data (NGD) Systems was founded in 2013 and builds a Catalina 2 flash drive using large amounts of Micron TLC 3D NAND flash, up to 24TB. It has had two known rounds of funding, $6.3m in 2016 and more than $10m in 2017.
The three founders – CEO Nader Salessi, CTO Vladimir Alves and EVP Richard Mateya – are SSD industry vets with time spent at STEC, Western Digital and Memtech in their CVs. NGD Systems was formerly called NxGnData and worked on adding an FPGA to a flash card before promoting the on-card compute to a multi-core ARM system.

Catalina 2 card
NGD Systems says it has the has lowest Watts per TB rating in the industry at less than 0.65 watts per terabyte.
The host server has a C/C++ library with an agent to handle the tunneling needed to talk to the drive across a PCIe 3.0 x4 link with the NVMe protocol. The drive SoC features an A53 Arm CPU, running Linux, and logic to handle ECC and FTL functions for the 12 M.2 flash modules.
Our understanding of the Catalina 2's main components shows the flash modules connected to the onboard Arm SoC.
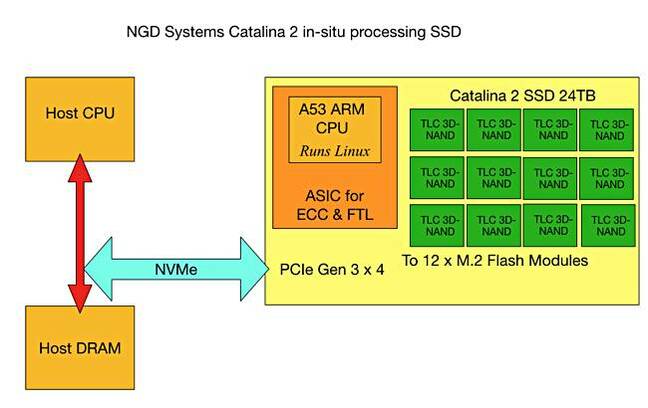
Salessi says of the Catalina 2 card: "Advanced applications like embedded AI and machine learning, which are by nature IO intensive, can run within the storage device."
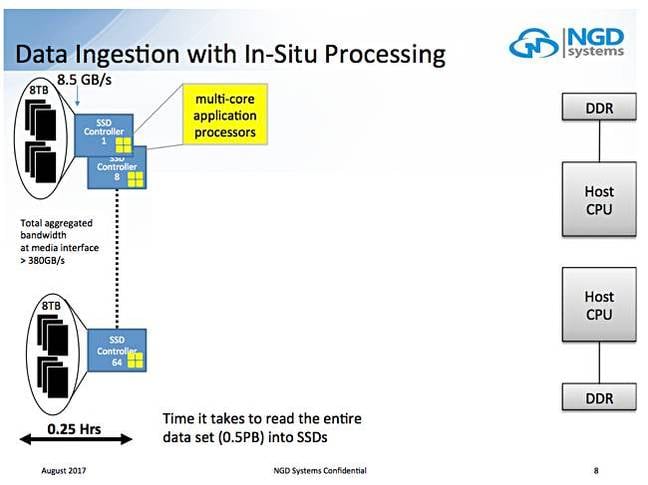
A Flash Memory Summit presentation, In-Situ Processing by Vladimir Alves, talks about a scenario where it takes 4.5 hours to read a 0.5PB data set into a 2-CPU server system fitted with 8TB SSD:
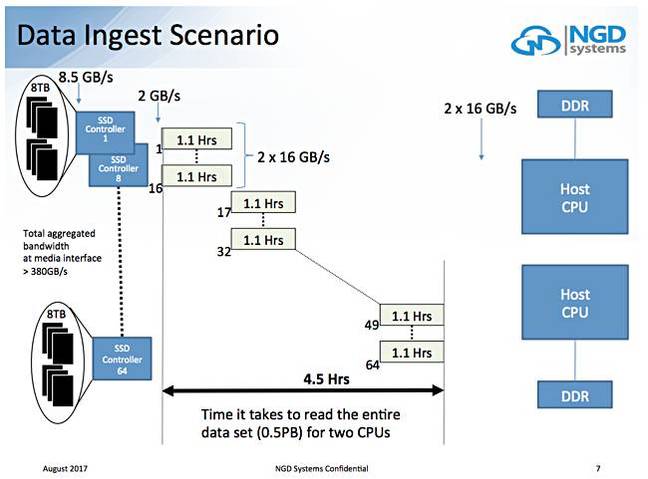
If those 8TB SSDS are replaced with 8TB Catalina-type drives then the ingest time drops to 15 minutes – an 8X speed increase with an aggregated bandwidth of more than 380GB/sec.
NGD Systems is still in stealth. We might expect it to emerge soon enough. A third startup is betting it will.
NVMeStorage
NVMeStorage promises a paradigm shift by moving compute to where the data is, and it's using Catalina cards.
Co-founder Jos Keulers blogged: "In Situ processing means that it has compute power on the drive itself where the data is being stored in the first place. The data does not leave the drive it is originally stored on.
"After it is stored it can do analytics at the exact location where the data is stored without having to transport the data off the drive. It can make local judgement of what data it need to send back to the cloud for big data analyses, do the protocol conversion and also it can clean the disk and remove the stored IoT data once that data is no longer useful or valuable."
He says such drives/devices can be used in fog computing: "The ideal place to analyze IoT data is as close to the devices that produce and act on that data. This is called Fog Computing."
Keulers added: "In Situ processing is the vital component here since the IoT data does not have to travel, guaranteeing a safe journey in the fog with NVMestorage.com powered by NGD Systems' Catalina In-Situ processing NMVe technology."
Read an NVMeStorage introductory doc here.
Bypassing problem with NVMeoF
NVMe over Fabrics is basically about banishing storage networking issues by having a host server access stored data using remote direct memory access (RDMA) and so, we might say, operate data IO, at double-digit microsecond speeds.
This effectively brings data to compute faster than before, and the compute is our old friend, the x86 server, meaning no programming problems from placing code on flash drive FPGAs or Arm processors, and no need to coordinate their activities.
With NVMeoF there is no need to develop special hardware to add compute to storage drives, meaning standard, commodity drives can be used.
Where we go from here?
We asked ScaleFlux marketing head Tian Jason Tian how NVMe over Fabrics will affect in-situ processing? Because it brings a storage array closer to servers, through RDMA-style connectivity, does it mean that you no longer need products like the CSS 1000?
He said: "Most applications today benefit from Computational Storage in scale-out/hyperconverged deployment models where Computational Storage can be directly connected in Compute servers. This provides the lowest latency and most evolutionary deployment model. As customers consider disaggregated storage, Computational Storage will provide even more value because local compute functions will not only save data movement to/from CPU/memory in the Compute server, but now, over the fabric."
How will technologies like SCM (storage-class memory) and NVMeoF affect in-situ processing?
He thinks: "Both SCM and NVMeoF have the promise to either enhance or expand the usage models of Computational Storage as explained above. As SCM matures, we see it working together with Computational Storage to expand the application set. From an NVMeoF perspective, processing in place at storage can save even more data movement in the data center saving power, cost and improving the responsiveness of data driven applications."
Nor does NGD Systems marketing head Scott Shadley think NVMeoF will render compute-capable flash drives irrelevant: "NVMeoF is still just getting more CPU access to each drive. It helps, but does not completely solve the bottleneck. It simply allows consolidation of where the storage is located, not making it any smarter or more efficient."
But does it solve the storage network bottleneck problem?
He says: "It is a needed next step that gets the all-flash array guys and server guys to sell more [and] larger drives, but doesn't actually scale as effectively since the number or cores is still not increasing. With CPU on drive, you get the multiple that is still missing."
On this view bringing compute to data has an element of host server CPU offload, similar to TOE networking cards, meaning TCP/IP Offload Engines. They had a well-defined thing to do, TCP/IP processing, but there is no equivalent storage-level activity, beyond low-level things like compression or erasure coding perhaps.
If compute-on-flash-cards carve out a role for themselves there will need to be an understood boundary between host storage processing and drive storage processing. That may be a moveable boundary, varying with general application type, but the vendors will have to be able to show significant and lasting value for their product technology in specific market areas for it to become self-sustaining. ®
